From EHDS requirements to runnable secondary-use pipelines — secure, auditable, and Spark-scalable.

WHAT PONTEGRA PROVIDES
Governed FHIR and OMOP processing with manifest-backed traceability and controlled output pathways
Pontegra helps organizations implement EHDS-aligned secondary use workflows:
- Secure analysis inside a SPE/TRE
- Auditable access and processing with run manifests and lineage
- Controlled outputs
All while enabling cohort building and dataset/feature extraction at scale and publishing dataset metadata to catalogs within EHDS networks.
Powered by: Studyfyr – The Governed Clinical Research Toolkit and Platform on FHIR and OMOP.
why thıs matters
Unifying Governed Processing and Publication
Secondary use programs are under pressure to deliver research value while maintaining governance, privacy, and auditability.
Common delivery gaps
- Permit and policy requirements are not connected to day-to-day analytics execution
- EHDS permits are documents, but execution needs operational controls
- Secure processing controls and output controls are handled as separate systems
- EHDS requires audit trails, but notebooks don’t generate manifests
- Reproducibility and traceability are fragmented across tools and teams
- EHDS requires airlock, but most TREs bolt this on late
This results in
12-18 month timelines, compliance incidents, researcher frustration.
Pontegra addresses this with a unified operating model for governed processing and controlled publication workflows.


Where Pontegra Fits in the Operating Model
Roles / Operating Model
Health Data Access Body (HDAB)
- Evaluates secondary-use requests and issues permit/authorization decisions.
- Defines approval conditions (purpose, allowed users, retention, policy constraints).
Health Data Holder
- Provides access to approved data scope under organizational/legal controls.
- Ensures provisioned study data matches authorized purpose and minimization rules.
Data User (Research Team)
- Submits study request with purpose, population intent, and data requirements.
- Executes approved analytics only within controlled workspace boundaries.
SPE/TRE Platform Operator (Studyfyr-enabled)
- Binds request/approval metadata to executable controls in the runtime.
- Enforces policy-aware pipelines, audit/manifest traceability, and controlled egress.
- Promotes only approved outputs as immutable published artifacts.
Governance flow
Governance decisions are converted into machine-actionable study controls, so policy intent is preserved from request to execution to publication.
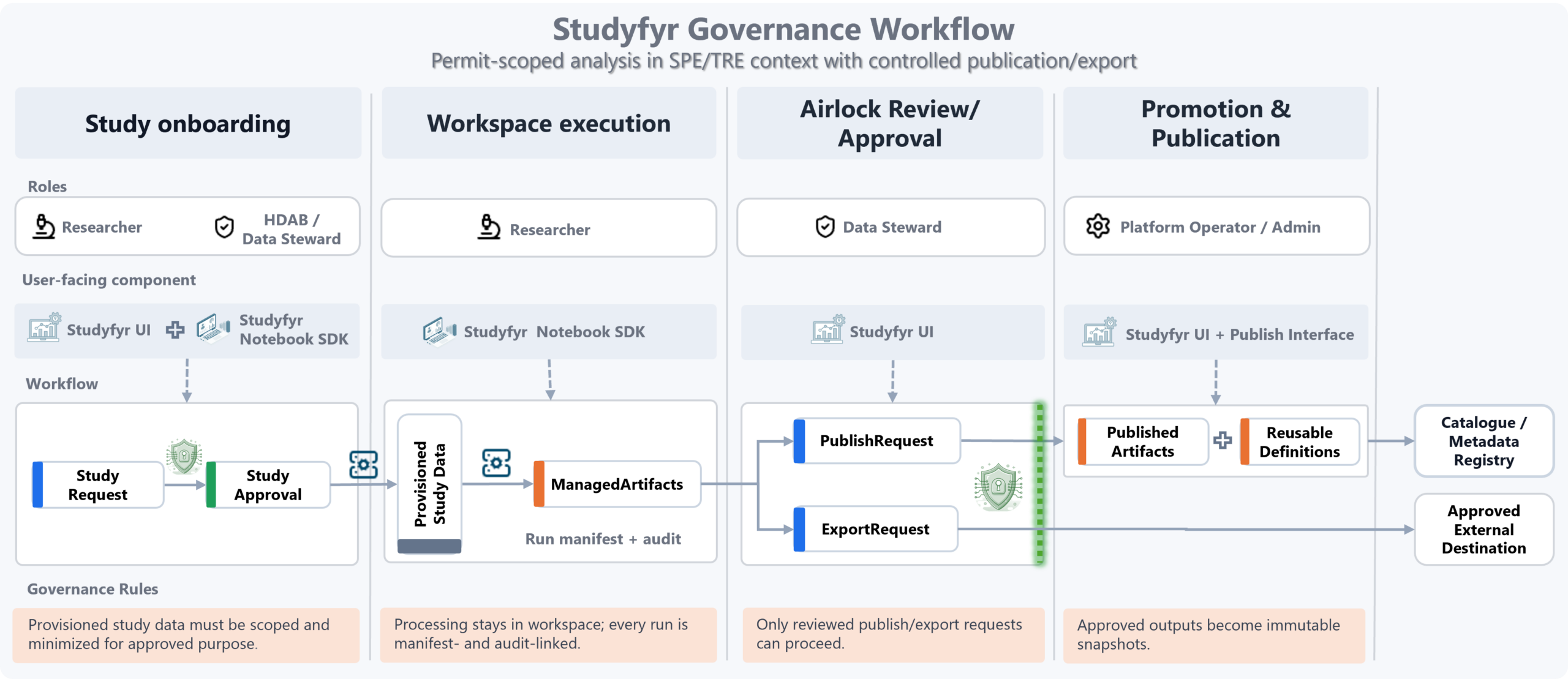
- Onboarding: request and approval define purpose/scope.
- Execution: processing stays in workspace with manifest/audit traceability.
- Airlock: publish/export requires steward review and approval.
- Promotion: approved outputs become immutable published artifacts.
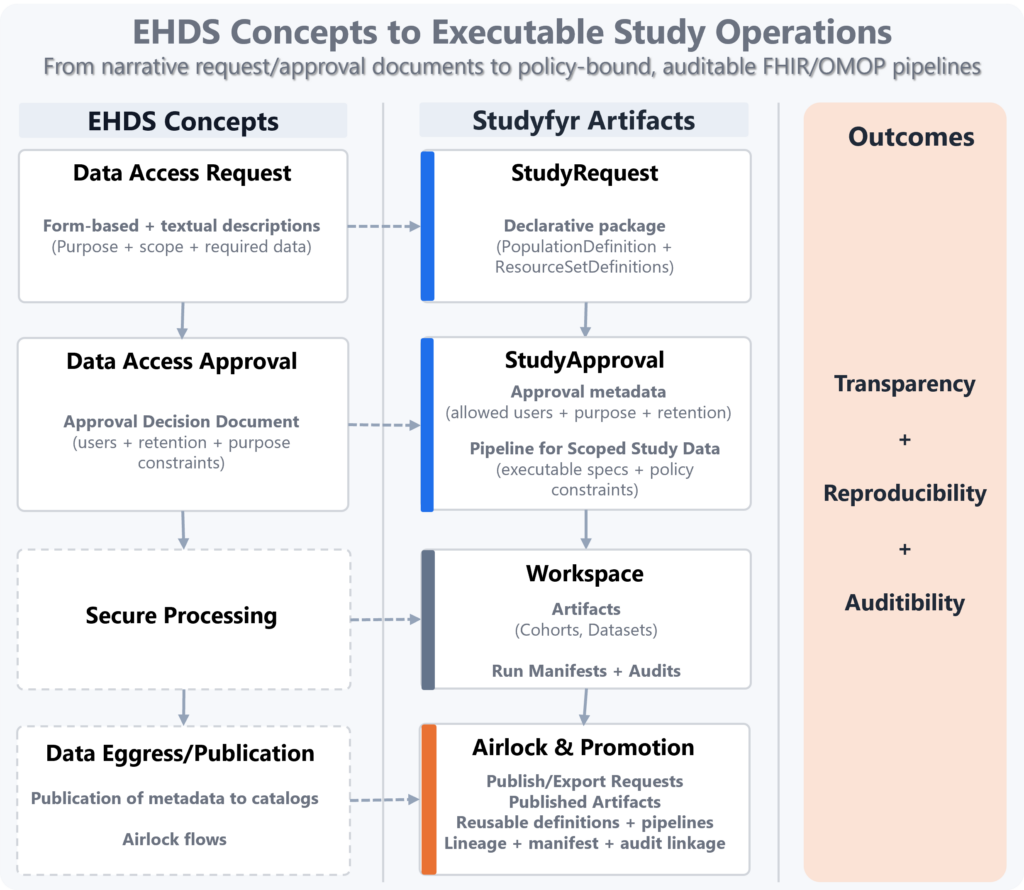
From EHDS Documents to Executable, Auditable Study Operations
Studyfyr binds EHDS governance concepts to executable data operations on FHIR/OMOP, so approvals are not only documents but machine-actionable controls. Result:
- Transparency: explicit request/approval-to-pipeline mapping.
- Reproducibility: the same approved definitions execute deterministically.
- Auditability: manifests and metadata audit events link decision, execution, and published outputs.
EHDS Alignment Checkpoints
| EHDS expectation | Pontegra implementation pattern | Typical evidence artifact |
|---|---|---|
| Permit-gated access and purpose limitation | Study-scoped workflows with explicit approval context | Run manifest with study/run metadata |
| Processing in secure environments (SPE/TRE model) | Controlled in-environment execution near data | Workspace/run records |
| Auditable access and activity | Metadata-first audit events plus immutable run history | Audit event stream + run manifests |
| Controlled outputs and egress | Airlock-compatible review and approval gates | Review decision records |
Note: EHDS-aligned implementation approach; not a blanket legal certification claim
Platform Capabilities
Secure Processing and Auditability
- Governed study workspaces with explicit lifecycle boundaries.
- Policy-driven minimization, anonymization, and pseudonymization controls.
- SPE/TRE-ready Spark execution on study-scoped data under environment controls.
- Manifest-backed run history and metadata audit events for traceability.
Controlled Outputs and Airlock Workflows
- Workspace artifacts (for example, cohorts and datasets) remain inside controlled storage by default.
- Publish/export actions require explicit review and approval (airlock-compatible flow).
- Approved outputs are promoted as immutable snapshots with lineage and audit linkage.
FHIR- and OMOP-Based Analytics at Scale
- Reproducible Spark processing foundations for secondary-use analytics.
- Data access from FHIR APIs, OMOP databases, and FHIR/OMOP lakehouse storage
- FHIR search/FHIRPath filtering and SQL-oriented extraction to analysis-ready tables.
- Unified processing model across FHIR and OMOP sources.
Research Workflow: Cohorts -> Sampling -> Features
- Repeatable cohort extraction with entry/exit/eligibility logic.
- Sampling strategies for periodic and event-aligned timepoints.
- Relational dataset preparation as reusable, well-defined tables/views.
- Feature dataset generation for statistics and ML, including longitudinal/windowed features.
- Deterministic run lifecycle supporting reproducibility and accountability.
WHERE THIS SOLUTION FITS BEST
Where This Solution Fits Best
National/regional secondary-use programs implementing EHDS-style governance
Hospitals and academic organizations operating SPE/TRE environments
Health data holders and platform teams needing permit-bound, auditable analytics
Research and RWE teams requiring controlled cohort-to-dataset workflows on FHIR/OMOP
SEE YOUR OPTIONS
Packages
Available now
Design Partner Track
- Best for: Organizations co-shaping early implementation priorities.
- Timeline: Ongoing
- Typical output: Use-case backlog, phased rollout plan, early access alignment.
Planned June 2026 *
Secondary Use Starter
- Best for: Teams ready to implement a first governed cohort-to-dataset pipeline.
- Timeline: 4-6 weeks
- Typical scope: One cohort definition, one dataset specification, pipeline implementation, run manifest/audit outputs, handover.
Planned October 2026 *
Secondary Use Scale-Up
- Best for: Multi-study rollout and recurring governed operations with Studyfyr.
- Timeline: 3-6 months
- Typical scope: Additional cohorts/datasets, scheduled refresh/recompute cycles, operating model hardening.
* Planned dates may be adjusted.