THE CHALLENGE
Scaling Data Access for Research
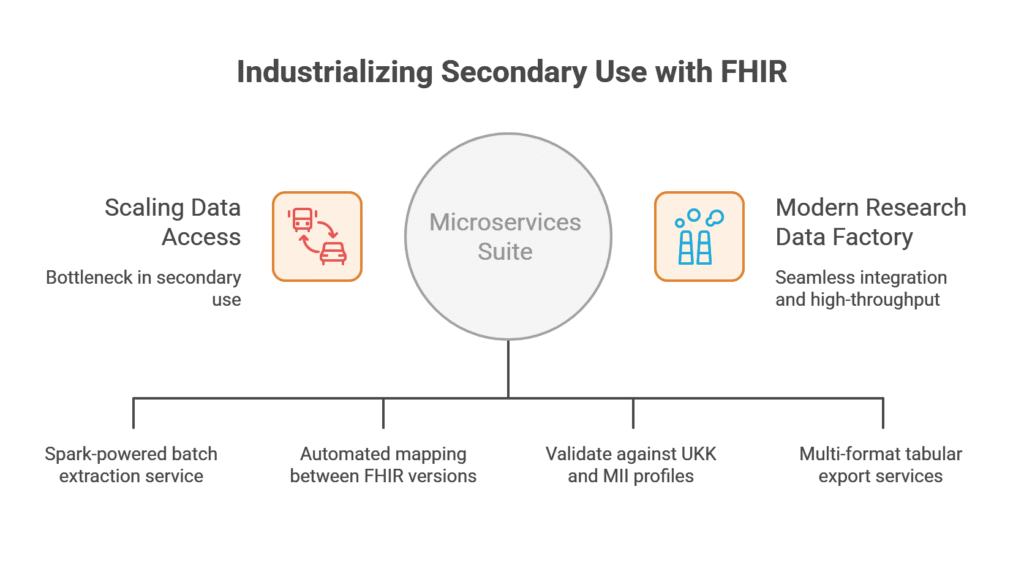
The University Hospital Cologne (UKK) Medical Data Integration Centre (MeDIC) required a robust mechanism to provide researchers with high-quality, analytics-ready clinical data. While the hospital had established a FHIR-native repository, the “last mile” of secondary use remained a bottleneck. Researchers needed a way to extract specific patient cohorts, validate that data against complex national profiles, and export it into high-performance tabular formats like Parquet and CSV for large-scale analysis.
THE SOLUTION
A Microservices Suite Powered by Ignifyr
We utilized Ignifyr to architect and deploy a suite of RESTful microservices designed for high-throughput data processing. This modular approach allowed the UKK team to integrate extraction, transformation, and validation steps directly into their existing data processing pipelines.
High-Performance Extraction and Transformation
Within the Ignifyr environment, we implemented specialized modules to handle massive clinical datasets with enterprise-grade efficiency:
- Spark-Powered Extraction: We utilized Ignifyr’s underlying Apache Spark integration to implement a batch extraction service. By configuring patient batch sizes and repartitioning strategies, we enabled the high-speed retrieval of FHIR resources from the central repository without impacting clinical operations.
- Complex Data Transformation: We utilized Ignifyr to execute sophisticated mapping jobs that can transform data between FHIR versions or into specialized research models. These transformations are managed through RESTful endpoints, allowing for fully automated, hands-off data preparation.
Automated Conformance and Validation
To ensure that exported data meets the rigorous standards of the Medical Informatics Initiative (MII), we utilized Ignifyr’s validation capabilities:
- Custom Profile Validation: We configured Ignifyr to validate resources against specific UKK and MII profiles, value sets, and code systems.
- Granular Severity Control: By utilizing Ignifyr’s validation logic, the system can be configured to filter results by severity, allowing researchers to prioritize “Fatal” or “Error” issues while maintaining a record of “Warnings” for data quality improvement.
Analytics-Ready Export Services
The final stage of the pipeline focused on making data usable for modern data science tools:
- Multi-Format Tabular Export: We utilized Ignifyr to implement an export service that translates hierarchical FHIR resources into flat formats such as CSV, TSV, and Parquet. This allows researchers to load clinical data directly into tools like R, Python, or specialized RWE platforms.
- FHIR-to-FHIR Synchronization: For cross-institutional projects, we utilized Ignifyr to enable secure exports directly to other FHIR servers, supporting the seamless flow of standardized data across the research network.
THE ımpact
A Modern Research Data Factory
The deployment of the Data Export Microservices at UKK MeDIC provided a production-grade bridge between the clinical repository and the research community.
- High-Throughput Analytics: By utilizing Apache Spark within the Ignifyr architecture, UKK can now process millions of resources in parallel, drastically reducing the time required to prepare large-scale datasets.
- Guaranteed Data Quality: The automated validation layer ensures that any data leaving the MeDIC environment is natively compliant with international and national standards.
- Seamless Integration: By wrapping every service in a documented RESTful API (Swagger/OpenAPI), we enabled UKK to orchestrate complex data flows through their central business process engines with minimal manual intervention.
SEE OUR PACKAGES
Are you looking to unlock clinical data for research?
See our packages to discover how we help institutions transform FHIR repositories into high-performance research data pipelines. Or contact us to discuss your specific data extraction and analytics needs.
STARTER PACK
MII Readiness Engagement
The Strategic Foundation for Your DIZ
Establish a validated, KDS-compliant data pipeline in 8–12 weeks. This fixed-scope engagement moves you from raw clinical data to a research-ready asset, providing the technical blueprint and institutional governance documentation required to kickstart your secondary-use strategy.
Planned June 2026 *
Secondary Use Starter
- Best for: Teams ready to implement a first governed cohort-to-dataset pipeline.
- Timeline: 4-6 weeks
- Typical scope: One cohort definition, one dataset specification, pipeline implementation, run manifest/audit outputs, handover.