Transforming Clinical Routine into Research-Ready Data at Scale.

WHAT PONTEGRA PROVIDES
KDS-Native Research Infrastructure
Pontegra helps Data Integration Centers (DIZ) and research organizations implement scalable secondary-use pipelines aligned with Germany’s Medical Informatics Initiative (MII).
We support ingestion and harmonisation to the MII Core Dataset (Kerndatensatz, KDS) in HL7 FHIR®, and enable reproducible cohort and dataset generation for research workflows.
Powered by: Ignifyr: High-fidelity mapping and ingestion from local EHRs to KDS-compliant HL7 FHIR®. Repofyr: A secure, FHIR-native repository optimized for research access and local governance. Or, we integrate your existing FHIR server. Studyfyr: A high-performance analytics engine for cohort discovery and the generation of analysis-ready feature tables.
Case Study: This impact is proven at the University of Cologne, where we industrialized laboratory interoperability by scaling from a pilot to a production environment processing millions of laboratory records using Ignifyr. [Learn more]
WHAT YOU CAN GET
Bridging the Gap Between Care and Science
Secondary use in Germany is unique due to its decentralized governance and strict adherence to the FDPG (Forschungsdatenportal Gesundheit). Our solution provides:
Audit-Ready KDS Compliance: Automated validation against published MII Implementation Guides and site-specific profiles.
Accelerated FDPG Fulfillment: Standardized processes to fulfill data requests from the national research portal with speed and precision.
Reproducible Research Pipelines: Shift from one-off SQL scripts to version-controlled, repeatable cohort definitions and sampling logic.
Analytics at Scale: Use Pontegra Secure Research Platform’s “SQL-on-FHIR” patterns to turn complex clinical resources into structured datasets for AI/ML and RWE.
EHDS Readiness: Future-proof your infrastructure with secure processing patterns that align with the emerging European Health Data Space framework.



Where This Solution Fits Best
Who is it for?
DIZ teams at university hospitals
Research IT / TRE teams running secure analysis environments
Consortia / projects requesting data across multiple sites
Life science / academic teams working with MII-aligned data access processes
WHAT IT IMPLIES TECHNCALLY
Why MII is different?
MII standardizes clinical content through a core dataset (KDS) and agreed to represent it in HL7 FHIR, supported by published implementation guides/profiles.
Operationally, data is held decentrally at sites, with local governance (e.g., Use & Access Committees), and requests are routed through the national research portal FDPG. This means DIZ teams need:
KDS-aligned data modelling and validation
consistent terminology handling across sites
repeatable cohort/dataset pipelines
secure processing patterns and controlled outputs
What Pontegra enables for MII / DIZ
KDS-aligned data modelling and ingestion
- Map source systems to KDS/FHIR modules and publish a clear transformation specification
- Validate generated resources against published KDS implementation guides/profiles and site-specific constraints where needed
- Establish incremental refresh patterns for routine-care updates
FHIR clinical repository & APIs for research use
Deploy a FHIR-native clinical repository/API layer (e.g., Repofyr) to support:
- controlled access for internal research pipelines
- consistent capability and search behaviour across datasets
- scalable downstream analytics and extraction
Cohort → sampling → feature datasets
Studyfyr turns KDS-aligned FHIR into reproducible research datasets:
- cohort definitions (entry/exit/eligibility logic)
- sampling (periodic or event-aligned timepoints)
- feature datasets and analysis-ready tables (SQL-on-FHIR-style extraction)
Data quality and feasibility at scale
MII teams often need quick feasibility insights and data quality checks across FHIR servers.
MII also maintains tooling focused on extracting metadata and identifying missing/incorrect values, underscoring how important this is operationally.
We help implement scalable profiling and checks as part of the pipeline (counts, completeness, code usage patterns, outliers).
FDPG-aware delivery (workflow alignment)
FDPG is the central portal for researchers seeking to access data and biosamples from MII sites.
We align deliverables to what DIZ teams need for request fulfilment: consistent KDS datasets, cohort counts, and curated extracts (while respecting local governance and security boundaries).
Use-case specific pipelines
The FDPG/MII ecosystem exposes data based on KDS modules; for example, public communication highlights modules such as Person, Diagnosis, Procedure, Laboratory, Medication, Consent, and Biosamples being queryable via FDPG.
We build pipelines around the modules relevant to your use-case and current site maturity.
How this connects to EHDS?
EHDS is an EU-wide framework for secondary use; MII is a German national ecosystem for research data access and interoperability.
In practice, DIZ teams benefit from the same core operational capabilities: secure processing patterns, auditable pipelines, and controlled outputs, implemented in a way that respects Germany’s decentral governance and processes.
OUR WORK IN ACTION
Featured Case Studies

University of Cologne
Automating the REDCap-to-FHIR Data Loop for Rare Disease Research

University of Cologne
Industrializing Laboratory Interoperability with Ignifyr
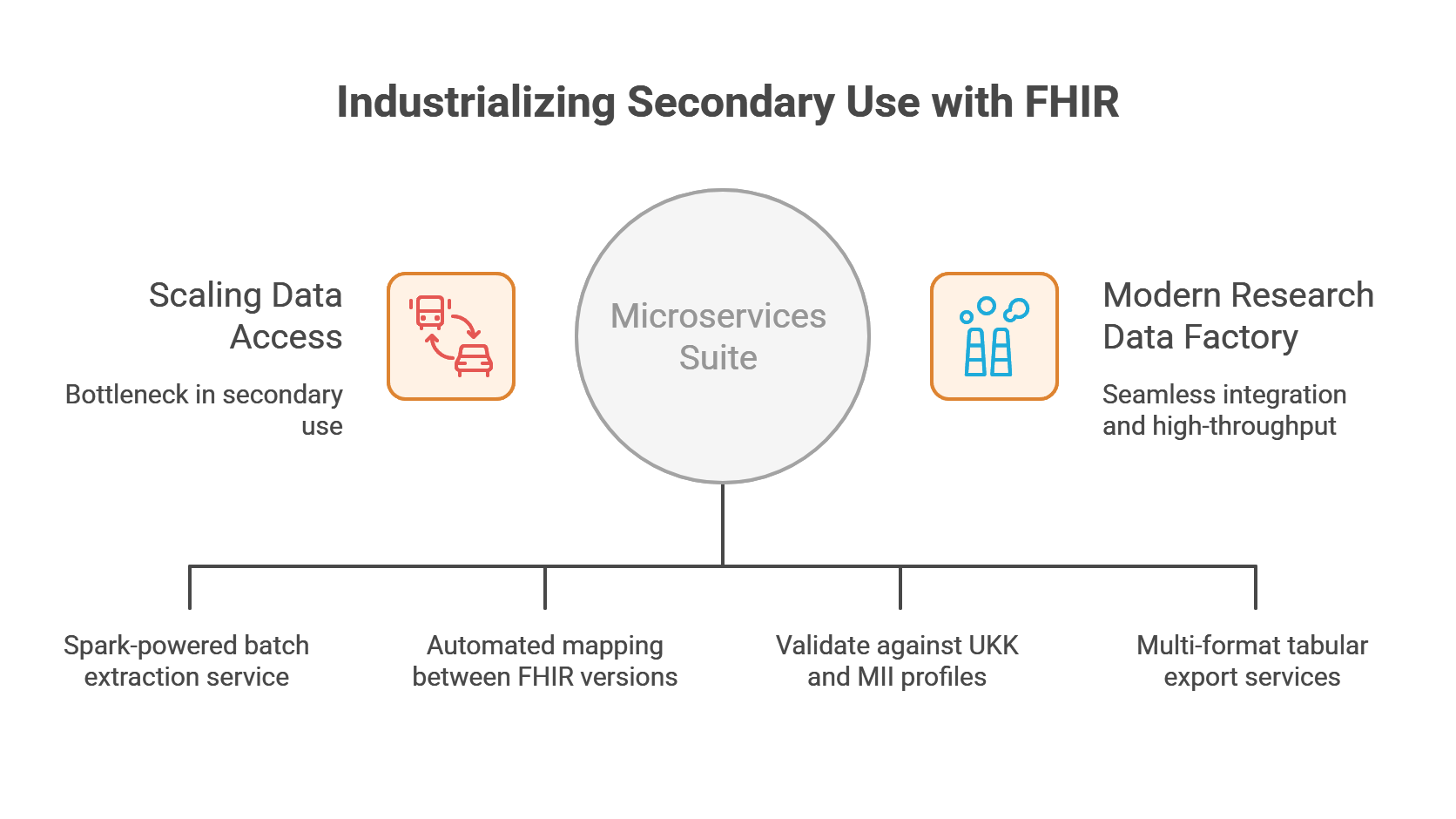
University of Cologne
Industrializing Secondary Use with Advanced FHIR Validation and Export Services
SEE YOUR OPTIONS
Packages
STARTER PACK
MII Readiness Engagement
The Strategic Foundation for Your DIZ
Establish a validated, KDS-compliant data pipeline in 8–12 weeks. This fixed-scope engagement moves you from raw clinical data to a research-ready asset, providing the technical blueprint and institutional governance documentation required to kickstart your secondary-use strategy.
PRODUCTION PACK
MII Production Rollout
Scale Your Research Factory to the Full Core Data Set
Transition from a pilot to an industrialized, high-availability production environment. This phase focuses on scaling your infrastructure to support the full MII Kerndatensatz, automating longitudinal data refreshes, and hardening your security posture for enterprise-wide research fulfillment.
OPTIONAL PACK
Managed Operations & Optimization
Proactive Oversight for Continuous Interoperability
Protect your investment with expert-led monitoring and triage. We take over the technical heavy lifting from daily pipeline execution checks and failure triage to terminology drift tracking. This ensures your platform remains performant.